What is this book and why does it exist?¶
This is a book that lives at the crossroads of heliophysics and machine learning. The authors are all heliophysicists that use the tools and techniques of machine learning to deal with large quantities of data in our daily work. This books sets out to show by example some of those real scenarios.
Why this book?¶
This book exists to act as a companion to published research in heliophysics that employs machine learning. This book shows you how to use open source packages for machine learning, statistics, and data minining together with various kinds of open access heliophysics data sets to reproduce scientific results published in refereed journals.
Here’s our driving use case: you read a scientific paper, wonder how exactly they produced those results, and then pull up the corresponding chapter in this book to see how to reproduce those results, with detailed explanatory text. You can optionally tweak things if you like to test e.g., the sensitivity of the results. More on reproducibility in a moment. Our main goal here is not to teach the theory of machine learning or to introduce heliophysics. There are numerous resources of exceptional quality for precisely that (see Other References for some starting points). However, this book can be used to teach others about machine learning and heliophysics by example. Maybe the examples herein will inspire you to try out something yourself. Or maybe you are looking for an example of how to, e.g., apply a support vector classifier to solar flare event data.
Reproducibility and open source scientific code have been garnering increasing attention recently. Nature surveyed scientists and found that nearly 70% of research in physics and engineering isn’t reproducible (Baker 2016). More than 50% of researchers in this category can’t even reproduce their own work. A third of labs across all scientific disciplines have no procedures for reproducibility. An important contributor to this problem has a simple solution. The respondents said that in 80% of cases, research is not reproducible because the methods or code are unavailable. So make the code available. That’s what we’re advocating for by example with this book.
There is a community push to make scientific code publicly available. For example, the American Astronomical Society Journals now have a statement on software for citation and have partnered with the Journal of Open Source Software to accept companion papers for software review. Much of the research community uses Jupyter notebooks as an excellent vehicle for sharing code. Finally, the National Academies of Science, Engineering, and Medicine published a couple reports that give us sense of which way the wind is blowing. One report is called Open Source Software Policy Options for NASA Earth and Space Sciences (2018). It recommends that the “NASA Science Mission Directorate should explicitly recognize the scientific value of open source software and incentivize its development and support, with the goal that open source science software becomes routine scientific practice.” Another report, called Reproducibility and Replicability in Science (2019), recommends that all researchers include a clear, specific, and complete description of how they got their results. They also ask funding agencies and organizations to invest in open source scientific software.
There are already recent examples of open source code that played a critical role in producing high-profile results in astrophysics. The Event Horizon Telescope data and VLBI image reconstruction code to generate the first ever image of a black hole is openly available and the same is true of the Laser Interferometer Gravitational-Wave Observatory data and analysis code used to obtain the first detection of colliding neutron stars. Reproducibility is fundamental to the ethos of science and code is often the most complete and explicit description of the methods employed to obtain a result.
But we also know that not everyone has the tools they need to create reproducibile research. A survey by The SunPy Project found that 99±0.5% of the solar physics community uses software in their research, but 63±4% haven’t taken any computer science courses at an undergraduate or graduate level. Many other scientific communities show the same trends, which is why the National Academies’ 2018 Report on Open Source Software Policy Options for NASA Earth and Space Sciences recommends that we help the Earth and Space Science communities learn how to use open source software. The SunPy Survey also found that most solar physicists use consumer hardware to run software their research, even though solar physicists build observatories and numerical models that generate ton of data. Only a small fraction of the community, 14%, uses a regional or national cluster. About 5% uses a commercial cloud provider. And nearly a third, 29%, use exclusively a laptop or desktop for their research. Finally, the survey found that most of the community, 73±4%, cites scientific software in their research, but only 42±3% do so routinely. Citing scientific software is extremely important – we cannot reproduce scientific results unless we know the exact version of each of the open source packages used in the analysis code. So hopefully this book helps with that, too.
Why heliophysics?¶
Simply put, we now live in a time with too much solar and solar-influences data for humans to digest. Recent and upcoming observatories generate petabytes of data, for example, from the Solar Dynamics Observatory launched in 2010 and the Daniel K. Inouye Solar Telescope. The datasets we have access to are varied and rich. The term Heliophysics System Observatory (HSO) was coined specifically to describe this. It consists of dozens of satellites spanning the solar system that observe a variety of heliophysical phenomena. While the HSO is comprised entirely of spacecraft, we have no shortage of ground-based observatories measuring the Sun and the Earth’s response to it. Together, these data span many decades and they vary wildly in terms of their resolution in time, space, and wavelength; and their measurement target: everything from radio to gamma ray light an entire zoo of atomic and molecular particles. More measurements of the Sun and its impacts exist now than at any time in human history. Nearly all of these data are freely available. There’s no indication that the firehose will constrict in the future. As a result, there’s little hope that humans will be able to glance at every single one of these observations and identify the connections and patterns contained within. Fortunately, we’re a clever species and are building tools that can do exactly that.
Why machine learning?¶
As with all computing, machine learning is, at its core, an augmentation of our natural capabilities. In particular, machine learning is good at handling large amounts of data, including disparate data and high-dimensional data. That is exactly the situation we find ourselves in with heliophysics data. Artificial intelligence isn’t putting us out of work, however. The main outputs of machine/deep learning tend to be identification and/or prediction, but the understanding can still only be found between keyboard and chair. It is up to us to determine if there is any physical meaning in the results. Nevertheless, we can leverage machine/deep learning to widen our discovery space. For example, analyzing data in its full dimensionality to find patterns without needing to first reduce it to something that can be plotted and understood on a screen is a major boon. Thus, we can leverage the strengths of our machines and our brains to develop more sophisticated analyses and gain a deeper understanding of nature.
What is machine learning?¶
Machine learning is not just modern computational statistics. The two disciplines were born half a century apart in vastly different computational landscapes. Traditional statistical programming came about when computational resources were highly constrained and, as a result, many of the techniques rely on various forms of simplification. A common example is figuring out an appropriate underlying distribution to describe some data. Simplifying assumptions of varying validity are made and it’s not always easy to quantify the impact of those assumptions.
Machine learning, on the other hand, became popular in an era where computing is cheap. Assumptions are still made, to be sure, but there’s much less restriction on initial assumptions. Instead determining what is important up front, we can leave many, if not all, of the numerous features of the data intact. This encourages exploration of data before subtle biases can cut out information that may have lead to new insights. Thus, while both use a computer to get the job done, the disciplines are vastly different in their approach and design.
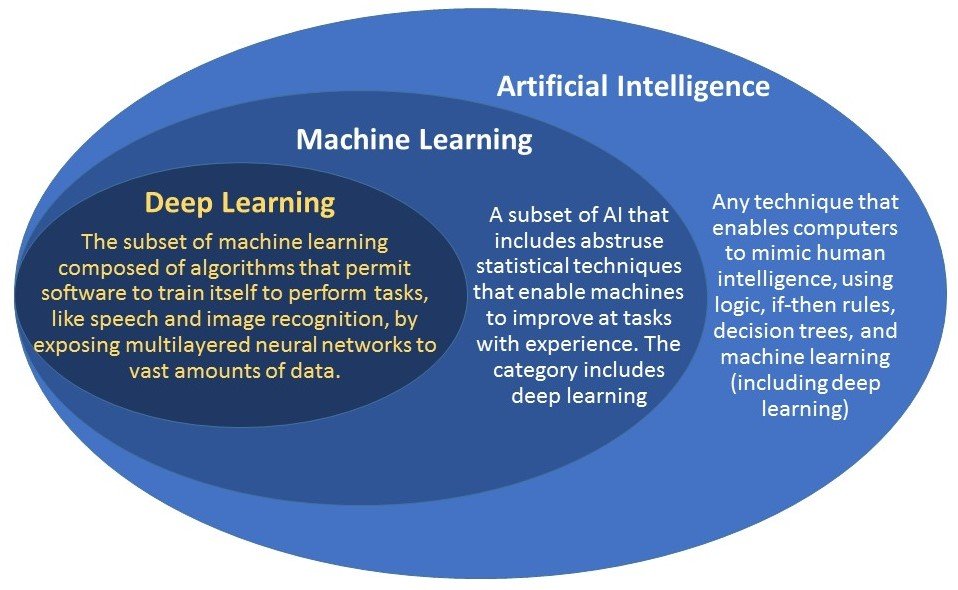
Just to get some high-level terminology out of the way as early as possible, see the image below (source). Machine learning is a sub-discipline of artificial intelligence. It generally requires that the user (the human in the chair) be a part of the overall learning feedback loop, e.g., how to quantify what is important and to determine success. Deep learning goes a step further in removing the human from the feedback loop by taking over that process as well.
What is heliophysics?¶
Heliophysics is a term that encompasses a lot. In short, it refers to the physics of the Sun and how its light and particles interact with everything in the solar system. Our focus tends toward interactions with planetary atmospheres and magnetospheres. This is critically important for us on Earth because space weather can adversely impact many of the technologies we rely on every day. For example, high-energy particles can damage GPS satellites. Farming, radio communications, and airlines all depend on high-precision Guidance and Navigation Satellite Systems (GNSS) like GPS. In fact, all satellites are vulnerable to solar storms, including communications satellites. Space weather also affects avionics, submarines, power grids, and astronauts. Fortunately, just as with terrestrial weather, accurate forecasts of space weather allow us to take measures to mitigate these impacts. We hope your ears perked up at the mention of forecasting, which is just a more probabilistic term for prediction.
But heliophysics isn’t all about making better space weather forecasts. It’s science. Many of us are in it for the joy of discovery and for contributing to humanity’s understanding of nature. Not only is it important for understanding the history and future of the solar system, it is also a microscope for the only solar system we know is capable of evolving and harboring life. How does the Earth’s magnetic field rapidly reconfigure itself during a solar storm? And how do these storms impact the ionosphere? What’s the composition of the solar atmosphere? And how hot is it, exactly? How do auroras behave on other planets? What if the Sun were smaller and dimmer? What if it was much more active – sending off even bigger disruptive eruptions and more often? How do storms on Sun-like stars in other solar systems affect extra-solar planets? Our ever deepening understanding of heliophysics informs our determination of whether these planets are potentially habitable. And in exchange, it provides us with context for our planetary relationship with our star and that most tantalizing question: Are we alone?